Shannonov kod
- Znake razvrstimo po padajočih vrednostih
- Dolžine kodnih besed:
- Kumulativne verjetnosti:
- Kodno besedo predstavlja prvih znakov za decimalno vejico
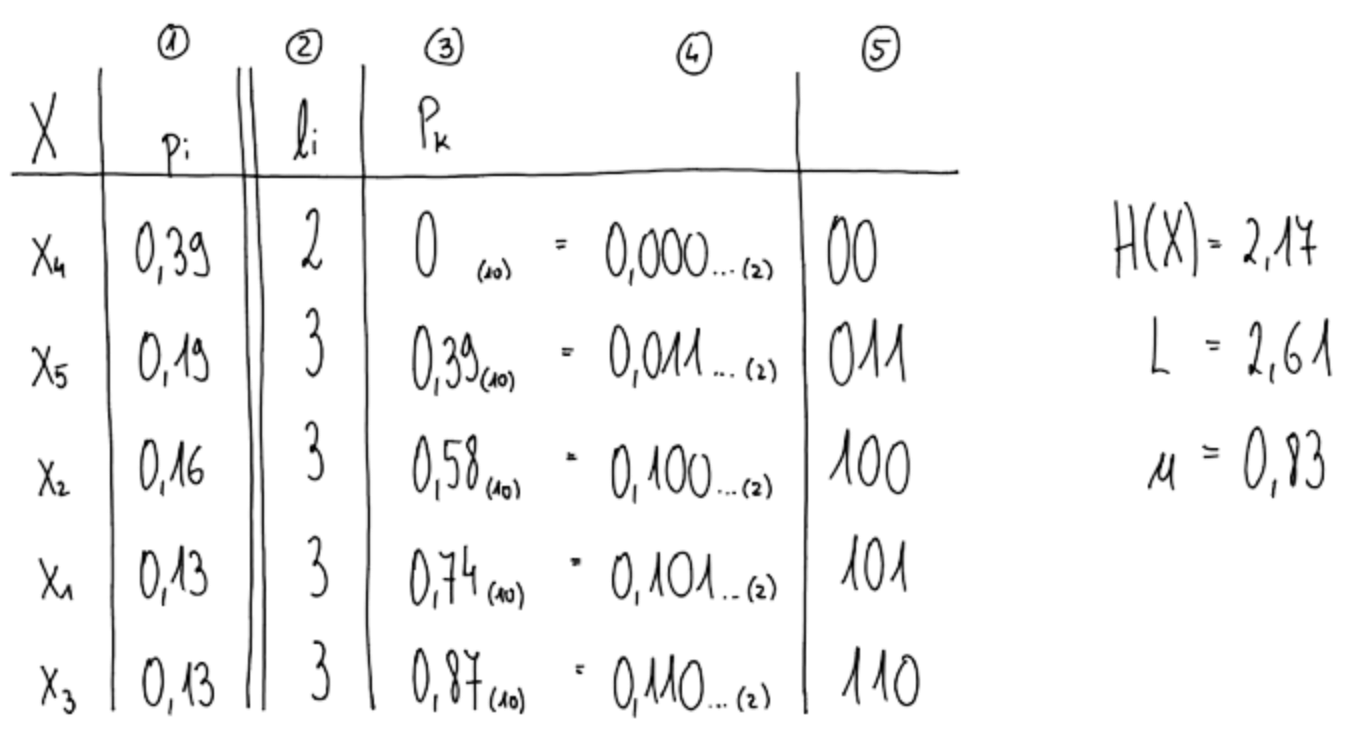
Shannon: Več osnovnih znakov združujemo v sestavljene znake, bolj se približujemo entropiji (a imamo zmeraj več znakov - kombinaciska eksplozija)
Fanojev kod
- Znake razvrstimo po padajočih vrednostih
- Znake razvrstimo v skupin s čim bolj enako vsoto verjetnosti
- Vsaki skupini dodelimo en znak kodne abecede
- Postopek ponovimo na vsaki novi skupini, dokler ni v vsaki skupini po 1 znak
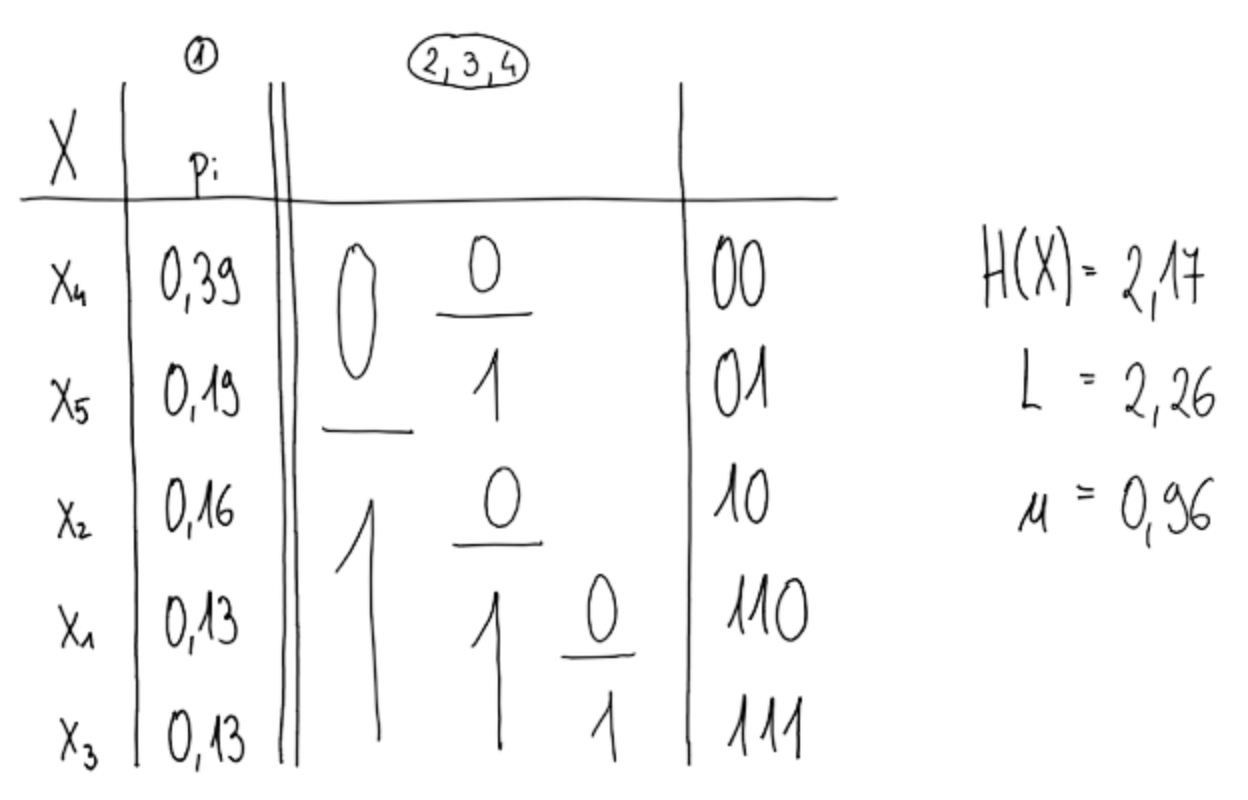
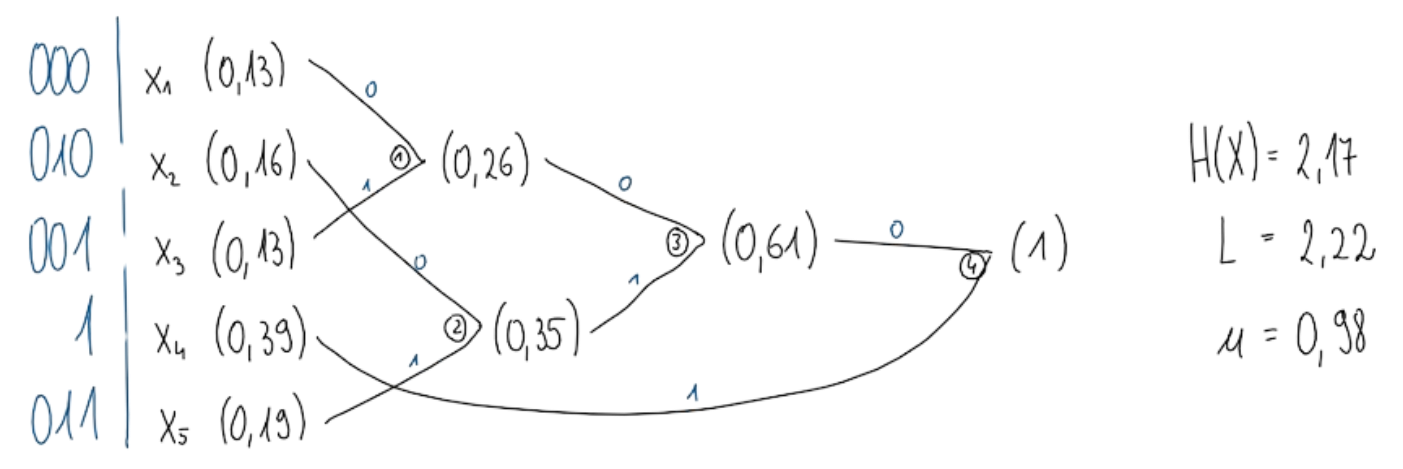
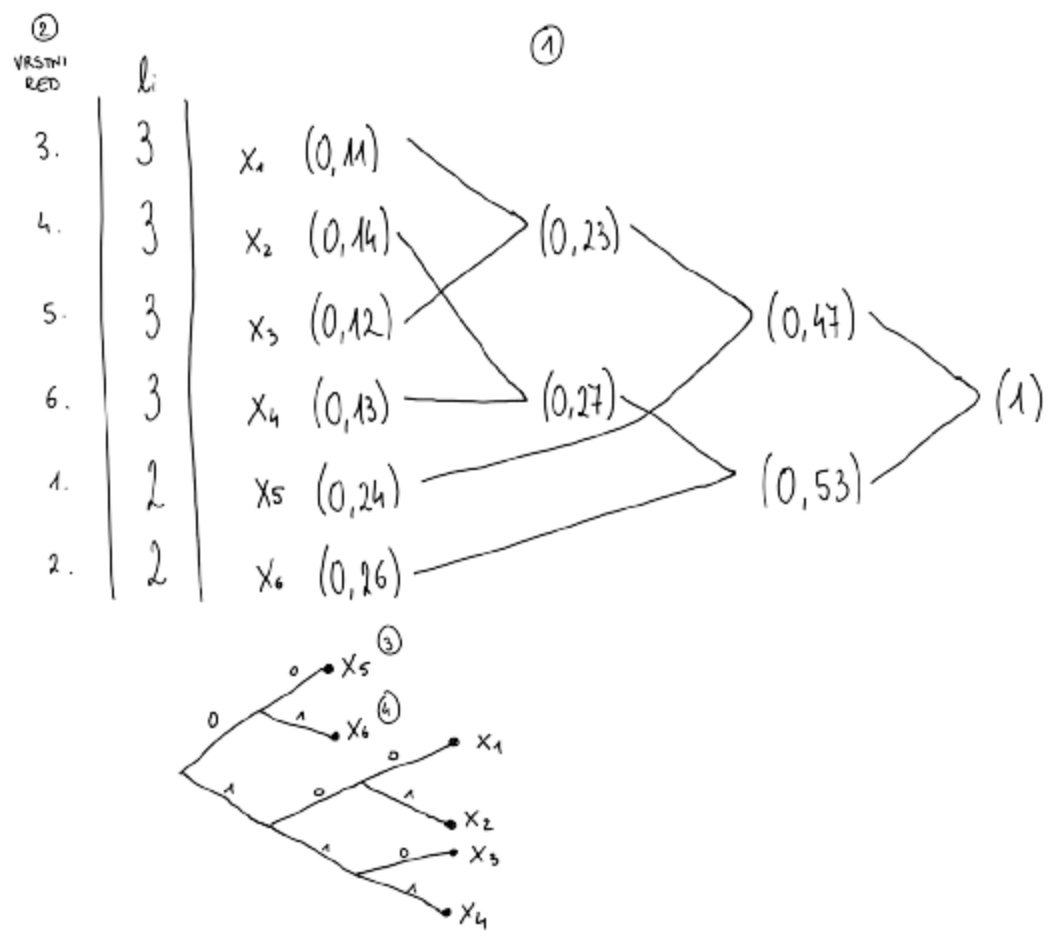
Huffmanov kod
Združevanje:
- Vzamemo najmanj verjetnih znakov
- Združimo jih v sestavljeni znak, katerega verjetnost je vsota verjetnosti vzetih znakov
- Postopek ponovimo, dokler ne ostane 1 znak
Razdruževanje:
- Sestavljeni znak razstavimo v znake, iz katerih smo ga sestavili
- Vsakemu priredimo enznak kodne abecede (veje)
- Postopek ponovimo, dokler imamo sestavljene znake
- Kodne besede preberemo od korena proti listom drevesa
Huffmanovi kodi so podmnožica optimalnih kodov, dokaz:
- Optimalen kod ne sme imeti neizrabljenih vej
- Najdaljše kodne besede so v -terčkih najmanj verjetnih znakov
- Osnovni kod = kod z združenima znakoma =
- Pri združevanju dobimo dva sestavljena znaka , bolj optimalen kod bi moram imeti manjši (kar ni mogoče)
Paziti moramo na neizrabljene veje - preveri, ali je dovolj znakov:
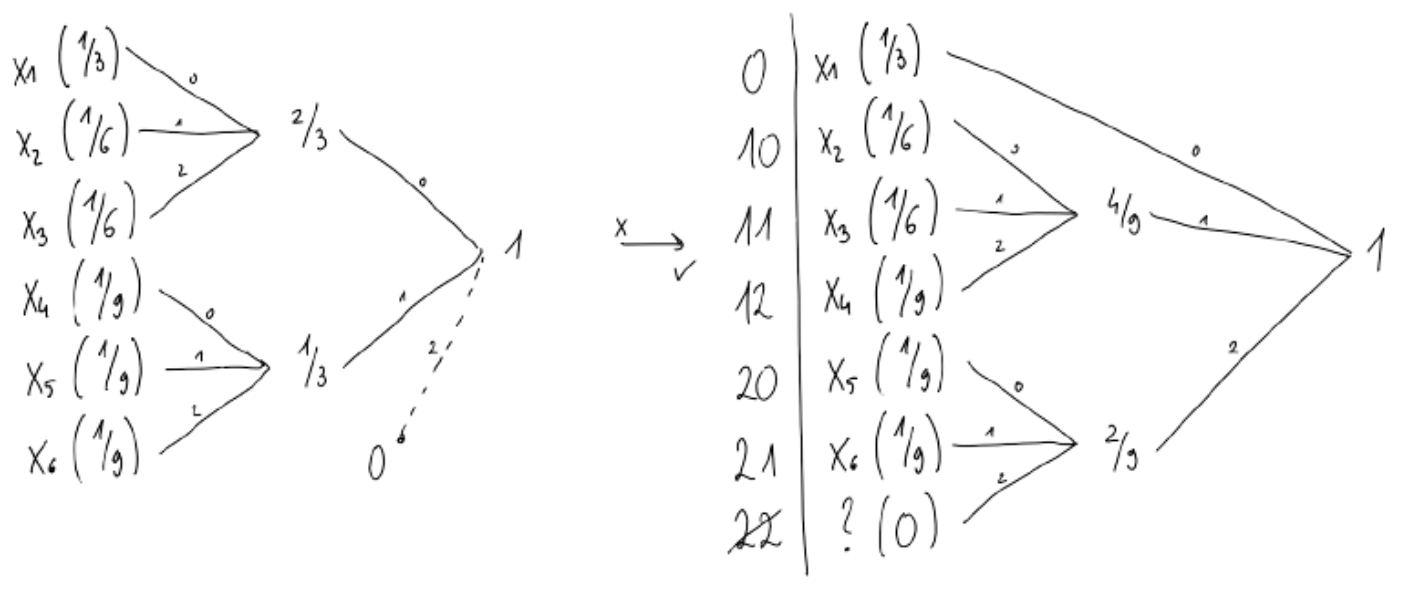
Kanonični Huffmanov kod
Enolična določitev Huffmanovega drevesa
- Zgradimo Huffmanovo drevo
- Znake razvrstimo najprej po dolžinah kodnih zamenjav naraščajoče, nato po abecedi
- Prvemu znaku priredimo same ničle
- Binarna koda naslednjega znaka: <koda prejšnjega znaka> + 1
- Če je koda naslednjega znaka daljša, na koncu dodamo ničlo
- Postopek ponovimo za vse zamenjave
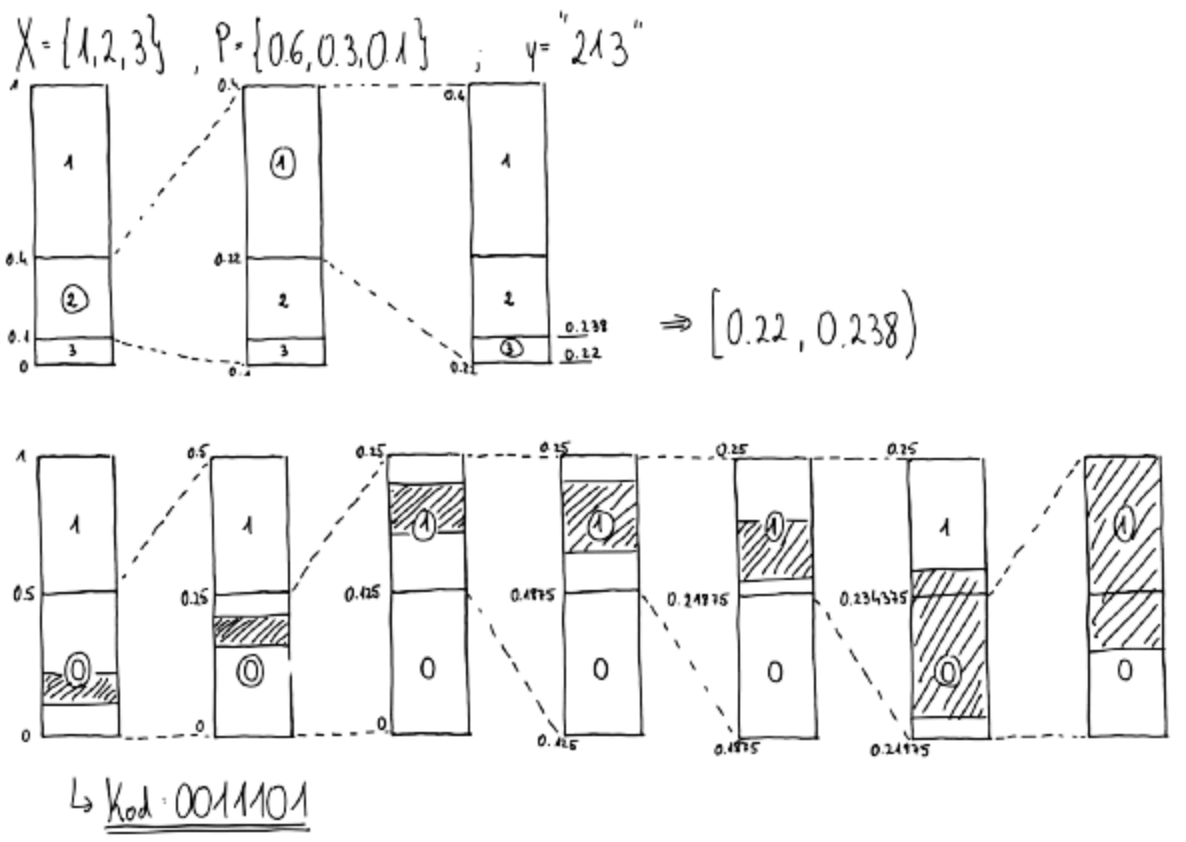
Aritmetični kod
Blizu optimalnemu kodu, hiter, ni težav s kombinacijsko eksplozijo
Ne tako učinkovit kot Huffmanov kod
Vsak niz je predstavljen kot realno število med 0 in 1 - z natančnostjo omogočamo dolžino niza
- Znakov ni treba razvrstiti
- Začnemo z intervalom
- Vsaemu znaku kodirne abecede priredimo podinterval, katerega velikost je sorazmerna verjetnosti znakov
- Izberemo podinterval, ki ustreza iskanemu znaku
- Postopek ponovimo na izbranem podinteralu
Stiskanje na osnovi slovarja
Konstrukcija slovarja na osnovi ponavljajočih se vzorcev - ne uporabljamo (vnaprej znanih) verjetnosti znakov
Kodirnik gradi slovar in zapisuje reference, dekodirnik rekonstruira slovar in znake
Kod LZ77
Kodirnik:
- preiskuje že poslana besedila, da poišče najdaljši (ponovljeni) niz
- namesto niza pošlje referenco na niz
- uporablja drseče okno z bralnim medpomnilniku in išče podobne nize v iskalnem medpomnilniku
Referenca: - odmik - razdalja od začetka enakega podniza v pomnilniku
- dolžina enakega podniza
- naslednji znak

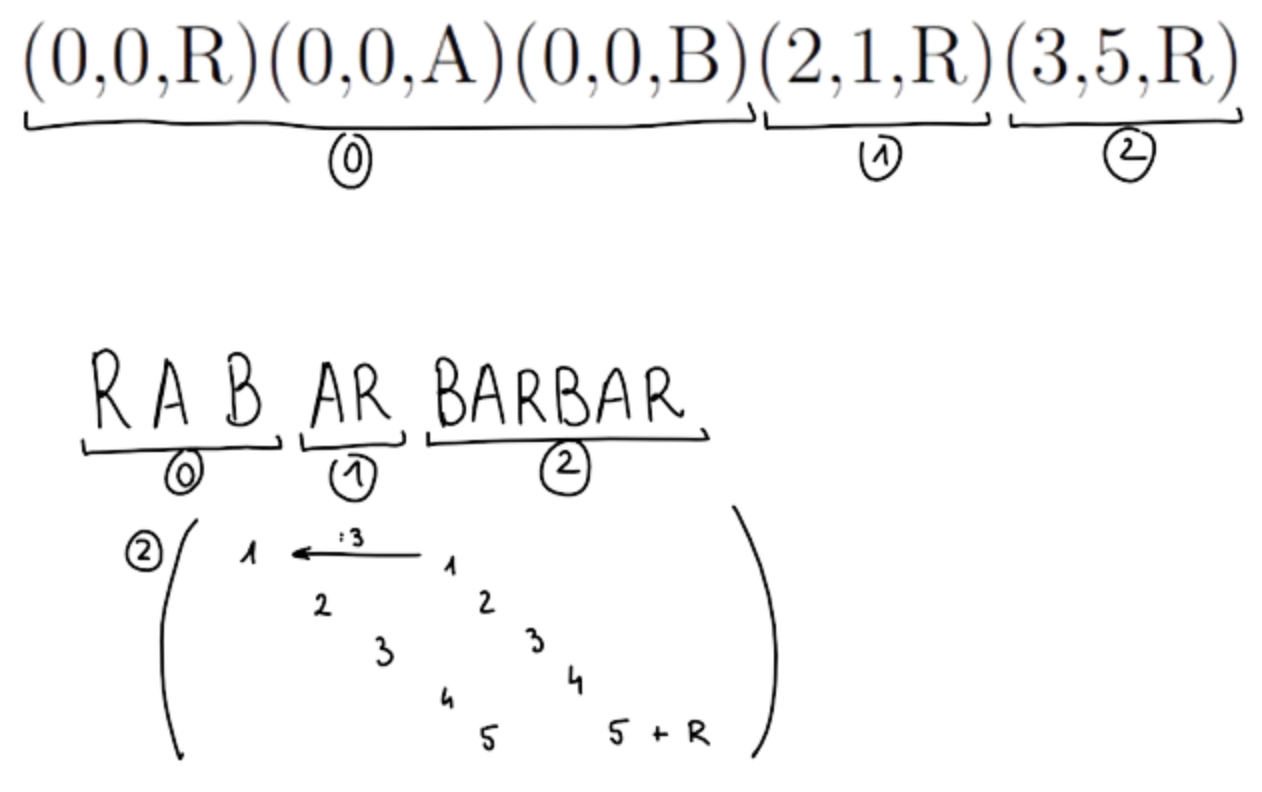
Kod DEFLATE
Predelan LZ:
- ali ponovljena osnovna znaka osnovni znak
- ponovljeni osnovni znaki par (odmik, dolžina)
Potrebujemo 2 kodni tabeli:
- tabela znakov: - osnovni znaki (dolžine 1), - konec bloka, - dolžine 3, …, - dolžine 10, …
- tabela odmikov: 5b enakomerni kod + do 13 dodatnih bitov (do 32000)
Niz znakov se razdeli na bloke, vsak blok se kodira na enega od treh načinov:
- brez stiskanja - osnovni znaki se prepišejo
- statični Huffman (vnaprej podane verjetnosti - hitrejše)
- Huffman (verjetnosti izračunamo - bolj stisnjeno)
Vsak blok ima glavo: 1b za označbo zadnjega bloka, 2b za tip stiskanja, v 3. primeru drevo (uporabimo kanonični Huffman za standardizacijo)
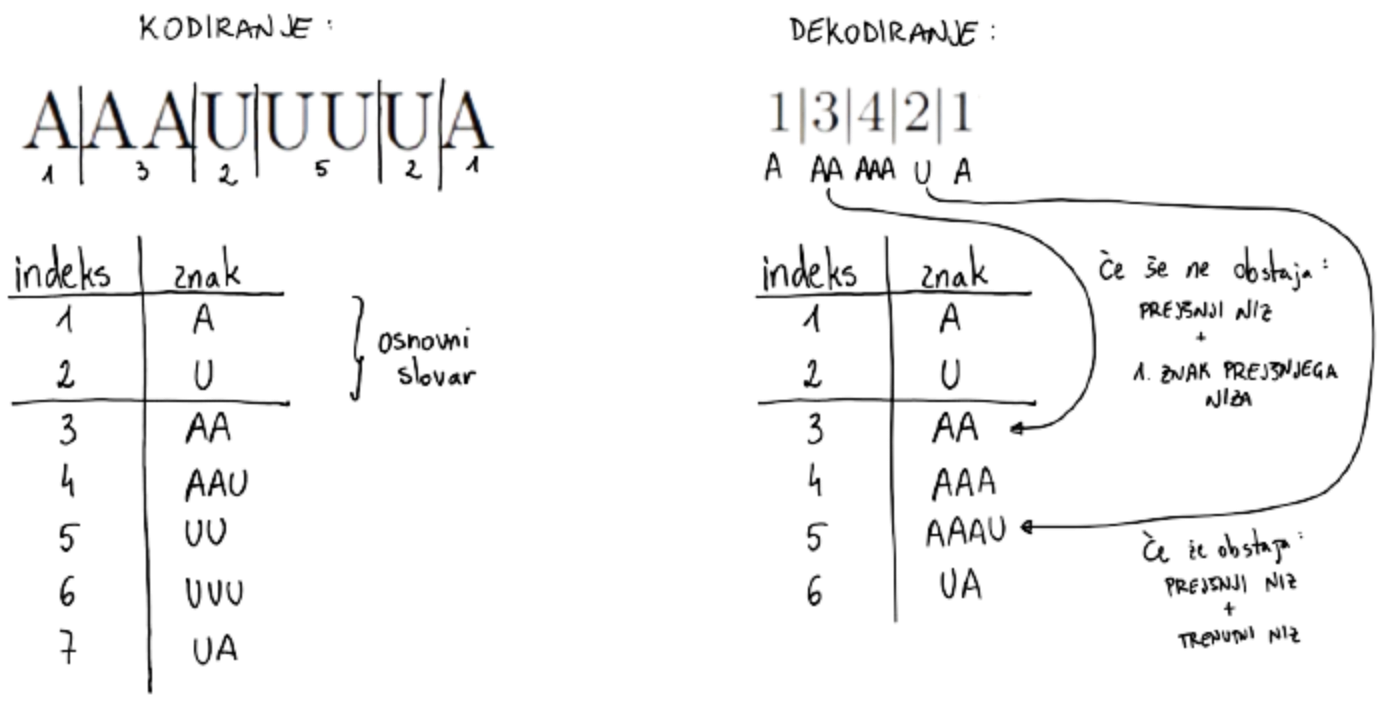
LZW
Doseže optimalno stiskanje, a rabimo velik slovar
Kodiranje: vnaprej definiran osnovni slovar sproti dopolnjujemo
Dekodiranje: med branjem rekonstruiramo slovar, vendar vedno zaostajamo za eno kodno zamenjavo ()
Verižno kodiranje
Izkorišča ponavljanje podatkov, namesto originalnih podatkov shranjuje dolžino verige
npr. aaaabbc 4a2b1c
BMP
- 1b za: 0 - verižno kodiranje / 1 - brez kodiranja
- št. znakov
- znak
Primer: 05a 04d 13edf aaaaaddddedf
Stiskanje z izgubami
Učinkovito pri slikah in zvoku - upoštevanje nepopolnosti človeških čutil
Kompresijsko razmerje:
JPEG
Shema: - svetlost in dve barvi, svetlost je pomembnejša
- Aprokcimacija vsake komponente z DCT
- Odrežemo nepomembne koeficiente (informacije)
- Predikcija na podlagi sosednjih točk z RLE
- S Huffmanom zakodiramo nove koeficiente
MP3
- DCT
- Odstranimo za človeka neslišne frekvence
- Odstranitev šibkih zvokov med glasnimi
- Če sta L in R podobna, se pošilja Mono
- S Huffmanom zakodiramo nove koeficiente
MPEG
Tipi okvirjev:
- I - cela slika: JPEG
- P - prediktivno kodiranje: poslane so spremembe in vektor premika (če ni veliko sprememb)
- B - interpolacija: kodiranje iz predhodnjega in nasldnjega okvirja
- D: močno stisnjen I