Samodejno izboljševanje algoritmov ob pridobivanju izkušenj gradnja modela z analizo učnih podatkov
Učni primeri so podani kot vrednosti vhodov in izhodov - označenih učnih primerov
Učimo se funkcije, ki preslika vhode v izhode: iščemo funkcijo … hipoteza, ki je najboljši približek funkciji
Vrste problemov
Klasifikacijski problemi
je diskretna spremenljivka - razred (končen nabor vrednosti)
Atributna predstavitev podatkov: vsak učni primer (vrstice) ima vrednosti atributov (stolpci)
Regresijski problemi
je zvezna spremenljivka - označba (npr. število)
Evalviranje hipotez
Prostor hipotez lahko vsebuje več hipotez, ki so konsistentne z učno množico
Dobra hipoteza je dovolj splošna: pravilno napoveduje vrednost tudi za še nevidene primere
Kriteriji evalviranja hipotez: konsistentnost (z učnimi primeri), splošnost, razumljivost
Točnosti hipotez: TP, TN, FP, FN
Klasifikacija točnosti:
Odločitvena drevesa
Odločitveno drevo: model, ki ponazarja relacijo med atributi in odločitvijo / ciljno spremenljivko:
- notranja vozlišča ~ pogoji glede na vrednost atributa
- listi ~ odločitev
- pot ~ konjunkcija pogojev na poti do lista
Cilj: gradnja čim manjšega drevesa, ki je konsistentno z učnimi podatki
Top Down Induction of Decision Trees
Hevristični požrešni algoritev:
- izberi najpomembnejši atribut - najbolj vpliva na klasifikacijo primera
- rekurzivno razdeli primere v poddrevesa glede na njihove vrednosti
- če vsi elementi v listu pripadajo istemu razredu, ustavi gradnjo
Požrešni algoritem je kratkoviden - izbira “lokalni” najboljši atribut, ne upošteva povezav med atributi, ki pripeljejo do optimalne rešitve
Iskanje najpomembnejšega atributa
Entropija / nedoločenost minimiziramo:
Informacijski prispevek maksimiziramo:
Večvrednostni atributi
Problem: informacijski prispevek precenjuje kakovost večvrednostnih atributov (višja entropija zaradi več vrednosti, namesto zaradi kakovosti)
Rešitve:
- Normalizacija informacijskega prispevka - relativni informacijski prispevek (information gain ratio):
- Uporaba alternativnih mer - Gini index:
- Diskretizacija / binarizacija atributov - zalogo vrednosti razbijemo v 2 / več diskretnih množic
Diskretni atributi: odločitvena drevesa delijo prvotno množico na vse manjše podmnožice
Zvezni atributi: delitev podmnožice glede na smiselno mejo izbranega atributa- intervali enake širine / z enako frekvenco primerov / maksimizirajo informacijski prispevek
- prostor tako delimo na particije (hiper-kvadre), katerih meje so vzporedne koordinatnim osem
Manjkajoči atributi
Učenje: ignoriramo / uporaba vrednosti NA/UNKNOWN / nadomestimo z npr. povprečjem
Napovedovanje: verjetnostna klasifikacija glede na vse možne vrednosti atributa
Uporabnost odločitvenega drevesa
Privzeta točnost: minimalna pričakovana točnost drevesa je verjetnost večinskega razreda v učni množici (če je manjša vzamemo kar splošno bolj verjetno opcijo)
Pretirano prilagajanje (overfitting): izguba splošnosti ob prevelikem prilagajanju učnim podatkom uporaba nevidenih/testnih primerov iz množice učnih primerov za sprotno preverjanje med gradnjo drevesa
Učenje dreves iz šumnih podatkov
Nepopolni podatki z napakami učenje šuma, slaba razumljivost, nižja klasifikacijska točnost, overfitting
Rezanje odločitvenega drevesa: posplošitev drevesa z rezanjem šumnih in pretirano prilagojenih nižjih delov drevesa
Strategije rezanja
Rezanje vnaprej (forward pruning)
Uporaba dodatnega kriterija glede na obseg šuma za zaustavitev gradnje drevesa hitrejše, a kratkovidno
Rezanje nazaj (post-pruning)
Po gradnji drevesa odstranimo manj zanesljive dele drevesa počasnejše, a upoštevamo informacijo celega drevesa
Rezanje z zmanjšanjem napake (Reduced Error Pruning)
Uporaba rezalne/validacijske množice primerne velikosti za zanesljivost (npr. vzamemo 30% učnih primerov)
Postopek:
- Potuj po vozliščih od vključno staršev listov drevesa navzgor
- št. napačnih klasifikacij v listih poddrevesa št. napačnih klasifikacij v vozlišču ohrani samo vozlišče (reži potomce)
Rezanje z minimizacijo napake (Minimal Error Pruning)
Uporaba učne množice (in ne ločene rezalne množice)
Cilj: minimizacija klasifikacijske napake / maksimizacija točnosti
Postopek:
- Za vozlišče izračunamo:
- statično napako - verjetnost klasifikacije v napačen razred
- ==vzvratno napako==
- Režemo, če:
- Napaka optimalno obrezanega drevesa:
Ocenjevanje verjetnosti
Relativna frekvenca: v listih z malo primeri ni dobra ocena (hitro spreminjajoča)
Ocena verjetnosti: boljša stabilnost z upoštevanjem apriorne verjetnosti: domensko znanje verjetnosti o problemu (npr. 50% pri metu kovanca)
Laplaceova ocena verjetnosti
Ne upošteva apriorne verjetnosti
- … št. primerov v razredu C
- … št. vseh primerov
- … št. vseh razredov
m-ocena verjetnosti
Posplošitev Laplaceove ocene za in
- … apriorna verjetnost razreda C
- … parameter vpliva apriorne verjetnosti ( linearno korelira z močjo rezanja)
Ocenjevanje učenja
Nasprotujoča cilja: potrebujemo hkrati čimveč podatkov za učenje in za ocenjevanje točnosti
- učnih podatkov dovolj naključno ali stratificirano izločimo testno množico
- učnih podatkov premalo večkratne delitve na učno in testno množico
Prečno preverjanje
k-kratno prečno preverjanje (k-fold cross-validation): najpogosteje
- Celo učno množico razbij na disjunktnih množic
- Za vsako od podmnožic izberi testno množico ostale so učne in vsakič oceni točnost
- Povpreči dobljenih ocen točnosti v končno oceno
Negiranje vpliva izbranega razbitja na podmnožice:
- večkrat ponovimo preverjanje z različnimi razbitji
- metoda izloči enega (Leave-One-Out): testna množica je 1 primer
Naivni Bayesov klasifikator
Bayesovo pravilo izraža diagnostično pogojno verjetnost na podlagi vzorčne pogojne verjetnosti
Verjetnost razreda (hipoteze) pri podanih vrednostih atributov:
Poznavanje velikega števila pogojnih verjetnosti verižnega pravila je v praksi težavno:
Zato predpostavimo medsebojno neodvisnost - dobri približki:
Bayesov klasifikator: primer klasificiramo v najbolj verjeten razred
- učenje: ocenimo verjetnosti in za vse razrede in vrednosti atributov
- napovedovnje: uporaba zgornje enačbe za napoved razreda novim primerom + normalizacija rezultatov (poenostavitev formule )
Nomogrami
Nomogram: grafična upodobitev numeričnih odnosov med spremenljivkami pristop k vizualizaciji naivnega Bayesovega modela
- pomembnost posameznih vrednosti vsakega atributa na ciljni razred
- pomembnost posameznih atributov na ciljni razred
Vsaka vrednost atributa doprinaša določeno št. točk k skupni vsoti točk, razpon točk atributa predstavlja pomembnost atributa na napoved ciljnega razreda
Izračun nomograma
Logistična funkcija: verjetnost na intervalu preslika na interval
Edino razmerje verjetja (Odds Ratio) je odvisno od vrednosti atributov uporabimo za točkovanje doprinosa atributa
Metoda k najbližjih sosedov
- neparametrična metoda - ne ocenjuje parametrov
- leno učenje - z učenjem odlaša vse do povpraševanja o novem primeru
- učenje na podlagi posameznih primerov
Metoda: poišči k primerov, ki so najbližji glede na podano mero razdalje
- klasifikacija napovej večinski razred
- regresija povprečna vrednost označb sosedov
Izbira k (običajno ):
- liho št. izognemo se neodločenim primerom
- premajhen / prevelik pretirano / prešibko prilagajanje
Mere razdalj:
- razdalja Minkowskega:
- evklidska razdalja:
- manhattanska razdalja:
Diskretni atributi Hammingova razdalja … št. neujemajočih atributov
Zvezni atribti razlika med vrednostma
- različno veliki intervali vrednosti normalizacija
- več dimenzij prekletstvo dimenzionalnosti … primere to naredi bolj odmaknjene
k najbližjih sosedov za regresijo
Naloga: najti k primerov, ki so najbližji glede na podano mero razdalje
Izračun napovedi utežena vsota: … utež
za funkcijo uporabimo poljubno jedrno funkcijo, npr. Gaussovo jedro
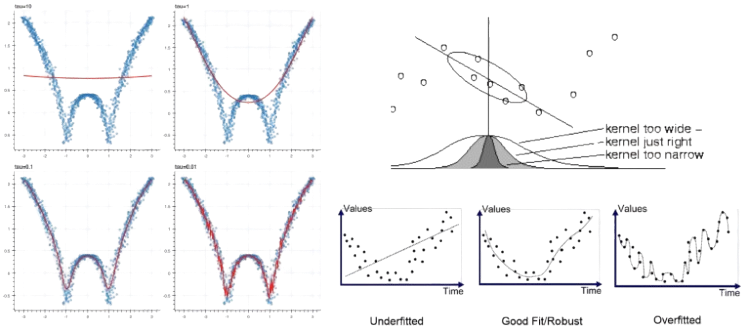
Regresijska drevesa
Listi v regresijskem drevesu zvezne ciljne spremenljivke predstavljajo nek napovedn model (npr. povprečno vrednost)
Srednja kvadratna napaka vozlišča v: mera nedoločenosti, ki jo želimo minimizirati
Pričakovana rezidualna nečistost:
Linearna regresija
Linearna regresija: iskanje funkcije z eno odvisno spremenljivko (in večimi utežmi), ki se najbolje prilega učnim podatkom
Računanje / optimizacija z minimizacijo srednje kvadratne napake:
Analitična rešitev:
Uporaba: klasifikacija - separator razredov / regresija - prileganje skozi podane točke
Posplošitev v več dimenzij
Več neodisnih spremenljivk:
Določevanje uteži:
- analitično:
- gradientni spust - približek, a veliko hitrejši od analitičnega

- … hitrost učenja
- … vrednost -tega atributa učnega primera
Linearni modeli pri klasifikaciji
Stohastični gradientni spust: preprosto iskanje rešitve s posodabljanjem uteži za vsak učni primer, hitrejše učenje kot pri klasičnem gradientnem spustu
- … ciljna vrednost
- … izhodna vrednost za učni primer
| rezultat | ||||
|---|---|---|---|---|
| izhod enak ciljni vrednosti | 0 | ni popravka | utež ostane enaka | |
| potreben popravek navzgor | >0 | utež povečamo za pozitivne utež zmanjšamo za negativne | ||
| potreben popravek navzdol | <0 | utež zmajšamo za pozitivne utež povečamo za negativne |
Nevronske mreže
Umetni nevron izračuna uteženo linearno kombinacijo vhodov in jo z aktivacijsko funckcijo preslika v izhodno vrednost
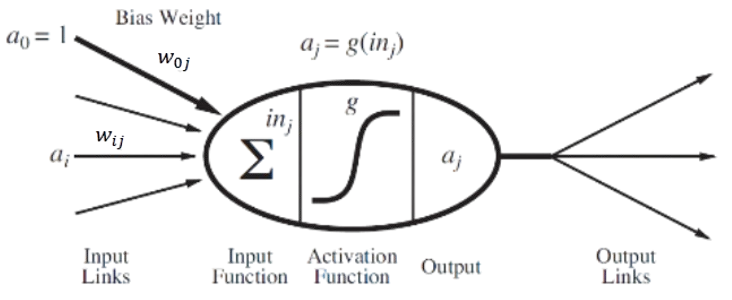
Nevronska mreža: medsebojno povezani nevroni lahko izračunavajo bolj kompleksne funkcije (medsebojno kombiniranje funkcij)
Implementacije:
- feed-forward network: aciklične povezave od vhoda proti izhodu - organizacija v plasti, možen en ali več izhodnih nevronov (napoved ene zvezne vrednosti ali klasifikacija)
- rekurenčna mreža: izhodi kot ponovni vhodi v mrežo dinamičen sistem z notranjim stanjem
- konvolucijske mreže
Vzvratno razširjanje napake
- Inicializacija uteži: majhne neničelne naključne vrednosti
- Izračun napovedi za učne primere
- Izračun izgube - funkcije napake na izhodnih nevronih
- Vzvratno razširjanje napake od izhoda proti vhodu: izračun gradienta napake za izhodni in skriti nivo
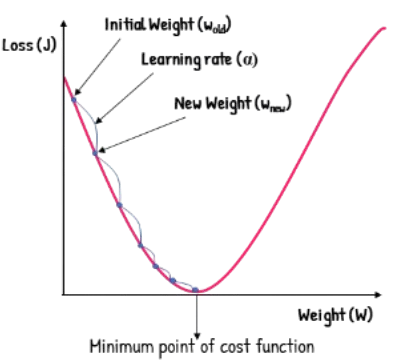
- Gradientni spust z določeno hitrostjo učenja za popravke vrednosti uteži po formuli
Ponavljaj korake 2-5 do ustavitvenega kriterija: izbrano št. epoh, znižanje napake do željene meje, …
Učenje nevronske mreže
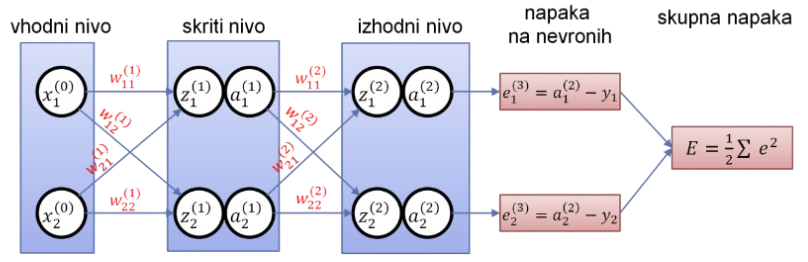
Ovrednotimo napako s primerjavo aktivacij nevronov izhodne plasti in ciljnih vrednosti
Cilj: minimizacija napake preko nastavljanja uteži