(Grafični) pospeševalniki

Niso popolnoma samostojni, a imajo svoje pomnilniške in procesne elemente
GPE
Grafična procesna enota / grafični pospeševalnik: primarno namenjen upodabljanju slik
General purpose GPU (GPGPU):
- CUDA (Nvidia): omejeno na Nvidia GPE, ni potrebe po konfiguraciji
- OpenCL (Kronos): zelo splošen, ob zagonu programa potrebno veliko inicializacije (preverjanja sistema)
Arhitektura
CPE: zaporedno izvajanje boljše pri vejitvah, rekurziji, …
- kompleksna kontrolna enota / splošen ALE / velik predpomnilnik
GPE: vzporednost boljše za vzporedne podatkovne tokove, matrične operacije, …
- veliko manjših kontrolnih enot / enostavni ALE / predpomnilniki
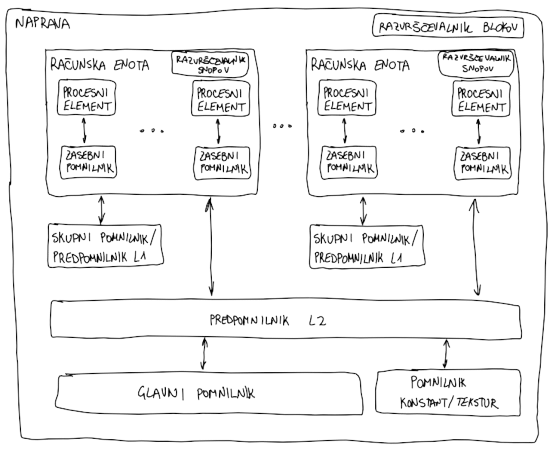
Hierarhična zasnova procesnih enot
Računsko hierarhično razdeljen: preprostejše razvrščanje
Računska enota: podobna kot jedro CPE, SIMD - izvajanje istega ukaza na različnih podatkih
Procesni element: podobno kot ALE na CPE, specializirane enote za celoštevilsko računanje in računanje v enojni ter dvojni natančnosti
Druge računske enote: posebne funkcije, npr. tenzorska jedra - matrično množenje
Kontrolna enota: prevzem in dekodiranje ukazov, razvrščanje ogromne množice niti na procesne elemente, prevzem in shranjevanje operandov
Hierarhična zasnova pomnilnikov
Pomnilniško hierarhično razdeljen: boljši dostopni časi, manj prekrivanja blokov med sabo ko rabijo podatke
Računska enota: procesne enote imajo zaseben pomnilnik/registre, L1 in skupni pomnilnik za izmenjevanje podatkov med nitmi znotraj računske enote
Naprava: predpomnilnik L2 skupen vsem računskim enotam, globalni pomnilnik za izmenjevanje podatkov s CPE
Izvajalni model
Programi sestavljeni iz:
- vzporedne kode na napravi - ščepec/jedro: koda zaporednega programa, ki se izvaja vzporedno na GPE (vsaka nit na svojih podatkih)
- zaporedne kode gostitelja: detekcija in inicializacija naprave, prenos ščepca in podatkov na napravo, sprožitev izvajanja na napravi, prenos podatkov nazaj na gostitelja
Postopek obdelave na GPE:
- Izberemo platformo in napravo
- Alociramo pomnilnik na napravi
- Procesor prenese podatke iz pomnilnika v pomnilnik naprave
- Procesor sproži izvajanje obdelave
- GPE izvede obdelavo, rezultate shrani v pomnilnik naprave in javi konec obdelave procesorju
- Procesor prenese podatke nazaj v pomnilnik gostitelja
Ozko grlo: prenos podatkov med gostiteljem in pospeševalnikom
Mreža niti:
- niti v mreži si delijo glavni pomnilnik
- sinhronizacijo delamo na gostitelju - ko vse niti zaključijo z delom se zaključek javi gostitelju
Blok niti:
- niti bloka se izvajajo na isti računski enoti (na kateri se lahko izvaja več blokov)
- niti bloka si delijo skupni pomnilnik za prenos podatkov in sinhronizacijo
- vrstni red izvajanja blokov ni podan - lahko celo zaporedno
Snop niti:
- manjša skupina (npr. 32) niti v bloku z zaporednimi indeksi
- vsaka nit ima svoj PC in zasebne registre - vsaka lahko zaporedno izvaja svoj program, a je izvajanje bolj učinkovito ob hkratnem izvajanju istega ukaza nad različnimi podatki
- ob čakanju snopa na dostop do pomnilnika se preklapljajo, pri čimer ni režijskih stroškov
Označevanje niti
